Building a Kafka-style commit log from scratch.
Recently I was learning how Kafka works internally. So in order to understand it, I built a commit log system from scratch in Golang.
Some people might think that Kafka is a message queue and not related to logs. But in reality Kafka is an append-only log system. I've discussed this more in this post.
In this post we will implement the log system discussed in the previous post from scratch.
A Quick Recap
A commit log is an append-only and immutable sequence of records. Commit logs are used in several software applications, including databases, message queues, event sourcing in microservices, etc.
It acts like a source of truth of actions performed in a system.
For example, inside Kafka, when a message is written to a topic, it gets written to disc by the concept of a commit log.
Store File
Inside our commit log there is a file with the extension '.store'. This file stores all the data written to the commit log. It follows a structure.
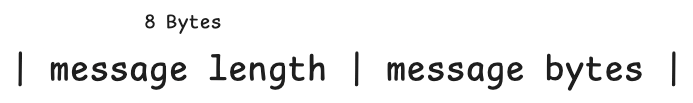
The 1st 8 bytes of this file store the length of the message. Let's say I want to store "Sushant". Its length is 7. So inside our store file, the first 8 bytes will store the number 7, and the next 7 bytes will store the actual data, which is "Sushant".
Offset
Every message stored in the commit log system gets a unique identifier called an 'offset'. Offset is helping us to fetch it from the store. Offset is an auto-increment number. The 1st message stored in the store will get offset 0, the 2nd will get 1 and so on.
Index File
Offset alone is not enough to fetch the message from the store file because we still don't know at which location it is stored. So we use an index file here. The index file stores the mapping of offset: position in the store file.
Reading Path
Whenever a read request is received, we first ask the index file at which position a message with this offset is stored in the store file. Once we get the position, we first read 8 bytes from that position in the store file. Why? Remember our store file structure. The 1st 8 bytes tell the length of the message. After that we read n number of bytes (n is the number stored in the first 8 bytes).
Enough Theory. Let's Code
store.go
package log
import (
"bufio"
"encoding/binary"
"os"
"sync"
)
var enc = binary.BigEndian
const lenWidth = 8
type store struct {
file *os.File
mu sync.Mutex
buf *bufio.Writer
size uint64
}
func newStore(f *os.File) (*store, error) {
fi, err := os.Stat(f.Name())
if err != nil {
return nil, err
}
size := uint64(fi.Size())
return &store{
file: f,
size: size,
buf: bufio.NewWriter(f),
}, nil
}
func (s *store) Append(data []byte) (n uint64, pos uint64, err error) {
s.mu.Lock()
defer s.mu.Unlock()
// Position at which current data is being stored.
pos = s.size
// This will write length of data in 8 bytes.
if err = binary.Write(s.buf, enc, uint64(len(data))); err != nil {
return 0, 0, err
}
w, err := s.buf.Write(data)
if err != nil {
return 0, 0, err
}
// w is the total length we have written for "data"
w += lenWidth
s.size += uint64(w)
return uint64(w), pos, nil
}
func (s *store) Read(pos uint64) ([]byte, error) {
s.mu.Lock()
defer s.mu.Unlock()
if err := s.buf.Flush(); err != nil {
return nil, err
}
size := make([]byte, lenWidth)
if _, err := s.file.ReadAt(size, int64(pos)); err != nil {
return nil, err
}
b := make([]byte, enc.Uint64(size))
if _, err := s.file.ReadAt(b, int64(pos+lenWidth)); err != nil {
return nil, err
}
return b, nil
}
func (s *store) ReadAt(p []byte, off int64) (int, error) {
s.mu.Lock()
defer s.mu.Unlock()
if err := s.buf.Flush(); err != nil {
return 0, err
}
return s.file.ReadAt(p, off)
}
func (s *store) Close() error {
s.mu.Lock()
defer s.mu.Unlock()
err := s.buf.Flush()
if err != nil {
return err
}
return s.file.Close()
}
Let's understand what's going on.
var enc = binary.BigEndian
This line is not just syntax, it’s important:
We are deciding how numbers are stored in bytes. When we write length (like 7 for "Sushant"), it is not stored as "7" — it is stored as 8 bytes in big-endian format. There are 2 types of formats. Big-endian and little-endian. We used big-endian because it is an agreed-upon standard for applications that operate on networks.
If you want to understand more about endianness, here is a great article for you.
const lenWidth = 8
We always use 8 bytes to store length. So even if data length is 5, we still reserve 8 bytes.
This makes reading predictable:
- First read 8 bytes → get length
- Then read next N bytes → actual data
Important parts:
file→ actual file on diskbuf→ buffered writer (performance boost)size→ current file size (very important for offsets)mu→ lock to avoid race conditions
The rest of the code is simple. Append() is writing our data as we want it to be written. After that it returns the number of bytes written, the position at which the write happened and the error if it occurred.
Read() is also simple. First we flush our file data. This is important because the OS buffers the data. So at the point of reading, data might be in memory, not in a file. Flushing forces the OS to store data from memory to file. Read() also gets the position at which we have to read. Rest is simple. Read the first 8 bytes from that position to get the size of the message and then read other n bytes which are equal to the size of the message.
index.go
/*
Data Structure for index
| 4 Bits store offset | | Next 8 bits store position |
*/
package log
import (
"io"
"os"
"github.com/tysonmote/gommap"
)
var (
offWidth uint64 = 4 // bytes
posWidth uint64 = 8 // bytes
completeWidth = offWidth + posWidth
)
type Config struct {
Segment struct {
MaxStoreBytes uint64
MaxIndexBytes uint64
InitialOffset uint64
}
}
type index struct {
file *os.File
mmap gommap.MMap
size uint64
}
func newIndex(f *os.File, config Config) (*index, error) {
idx := &index{
file: f,
}
fi, err := os.Stat(f.Name())
if err != nil {
return nil, err
}
idx.size = uint64(fi.Size())
/*
Truncating because later we are mapping this file in memory for faster access.
Truncating won't be possible once file is mapped to memory.
*/
if err := os.Truncate(f.Name(), int64(config.Segment.MaxIndexBytes)); err != nil {
return nil, err
}
m_map, err := gommap.Map(
idx.file.Fd(),
gommap.PROT_READ|gommap.PROT_WRITE,
gommap.MAP_SHARED,
)
if err != nil {
return nil, err
}
idx.mmap = m_map
return idx, nil
}
func (i *index) Close() error {
// This flushes memory mapped data to disk.
if err := i.mmap.Sync(gommap.MS_SYNC); err != nil {
return err
}
// Even after mmap sync, the OS may still have data in cache.
// We are forcing OS to flush file to presistent storage.
if err := i.file.Sync(); err != nil {
return err
}
// We again need to truncate because when opening this file inside newIndex() we truncated it to config.Segment.MaxIndexBytes
// this was done to memory map it. But during restart this will cause issue.
// If we keep file truncated to config.Segment.MaxIndexBytes it will have some garbage data in file and when we restart this application our next offset will be incorrect.
if err := i.file.Truncate(int64(i.size)); err != nil {
return err
}
return i.file.Close()
}
func (i *index) Write(off uint32, pos uint64) error {
if uint64(len(i.mmap)) < i.size+completeWidth {
return io.EOF
}
enc.PutUint32(i.mmap[i.size:i.size+offWidth], off)
enc.PutUint64(i.mmap[i.size+offWidth:i.size+completeWidth], pos)
i.size += uint64(completeWidth)
return nil
}
func (i *index) Read(off int64) (out uint32, pos uint64, err error) {
if i.size == 0 {
return 0, 0, io.EOF
}
if off == -1 {
out = uint32(i.size/completeWidth) - 1
} else {
out = uint32(off)
}
pos = uint64(out) * completeWidth
if i.size < pos+completeWidth {
return 0, 0, io.EOF
}
out = enc.Uint32(i.mmap[pos : pos+completeWidth])
pos = enc.Uint64(i.mmap[pos+offWidth : pos+completeWidth])
return
}
func (i *index) Name() string {
return i.file.Name()
}
Inside our index file, data is stored in the following format:
| 4 Bytes | 8 Bytes |
An offsetset for every message can be stored in the first first 4 bytes,, and the nextnext 8 bytes storethe actualtual position of that message in the storetore file. So a single index entry will be 12 bytes long. As we know that writes are sequential and offsets are auto-incremented, we can easily query the index file.
For example, if we want to know the message with offset 5, we can simply do math:
5 * 12 = 60So bytes numbers 60 to 71 contain information about the message on the 5th offset. Where bytes 60 to 63 contain the offset number and bytes 64 to 71 contain the position of the message in the store file.
Segmentation
type Config struct {
Segment struct {
MaxStoreBytes uint64
MaxIndexBytes uint64
InitialOffset uint64
}
}We can't store unlimited messages in a single file. So we split up files in segments. A segment contains a store file and an index file. We are not learning about segmenting in detail in this post. Just understand that segments are used to split data into multiple files instead of having one big single file.
For example, a segment can be seen as the following:
00000000.store
00000000.index -> Segment 1
00010000.store
00010000.index -> Segment 2Segment 1 stores messages with an offset from 0 to 9999, and segment 2 stores messages from offset 10000 and above.
type index struct {
file *os.File
mmap gommap.MMap
size uint64
}Everything is familiar to you except 1 thing, mmap.
Memory Mapping
It is a technique in which we map any file into virtual memory. When you are writing or reading a file, we need to use system calls, which are slow. But with memory mapping, instead of using slow read/write system calls, the application reads/writes data directly to disc via memory pointers. It's like treating our file as an in-memory array.
newIndex() This function creates an object of the index struct. There are few important things here to understand. Before memory mapping our file, we are truncating our file to the maximum size allowed. This is done because once we memory-map our file, we can't truncate it. Truncating is simple. Let's say our index file is empty and we defined the max size of the index file to 1024 bytes. Truncating will then add 1024 zeros to this file.
Similarly, if a file currently has 200 bytes of data, it will add 824 zeros at the last of the file.
Then we use Gommap. Map the library to memory map our file.
Writing is simple. As we are treating this file as an array via a memory-mapped file, we just use indexes to write content. We wrote the offset in the first 4 bytes and the position in the next 8 bytes.
Reading is also simple. If the offset provided is -1, we start reading from the end of the file; else, we just use our simple multiplication method to read content from the index. Once we get content from the index, we go to the store file to fetch actual data from it.
One important thing to understand is the Close() method. While closing, we are again truncating our file to the variable size of our index. The size variable holds the size of meaningful data in the file. This is important to do. Imagine a scenario where the server restarts and tries to load this file again; it will see its size is maximum because we added all zeros for memory mapping.
So this is how a simple commit log works. I hope you enjoyed this post. I like connecting with new people. I can be found on LinkedIn.
Before You Go
If you made it this far, Thank You.
I usually write about backend engineering, distributed systems, and things I learn while working on real problems. Not theory — mostly practical stuff that I wish someone had explained to me earlier.
I run a free newsletter where I share these kinds of write-ups. No spam. Just occasional backend engineering notes.