Kafka Fundamentals - Guide to Distributed Messaging
Why Kafka Exists?
You are building a backend system with multiple services (auth, payments, notifications, analytics). Each service needs to communicate with other services. Issues come when Service A needs to call Service B, and if Service B is down, Service A also fails. This type of communication increases system complexity and scaling problems. This is why Kafka is built.
Kafka introduces a new paradigm; instead of sending requests and waiting for responses, Kafka lets you treat data as a continuous stream of events. You publish events, allowing others to consume them independently.
What Kafka Provided?
- Decoupling at Scale - By using Kafka, your services do not need to establish direct communication with other services; instead, they push events in Kafka, and other services receive them independently.
- Massive Throughput - Kafka is built for massive throughput. It can handle millions of messages per second.
- Durability - Kafka is durable. Messages are not deleted once consumed. This gives us the ability to replay the events and rebuild the state of the system.
- Fault Tolerance - Data is replicated on several nodes; in case any nodes go down, the system will still continue to work.
What is Kafka?
Apache Kafka is a distributed event streaming platform used to handle real-time data feeds at massive scale. Think of Kafka like a high-speed messaging system where producers send messages, Kafka stores messages, and consumers read them. But unlike traditional messaging systems, Kafka is built for high throughput, fault tolerance, scalability and real-time processing.
Kafka vs Traditional Message Queues
Kaka is very different from traditional message queues. Traditional message queues are built for task distribution; they tell who will process the job. But Kaka is built for event streaming that says what happened and who all should know. In traditional queues a message is deleted once a consumer processes it, but in Kafka it is retained so that we can replay the events if we want. Traditional message queues also fall behind when it comes to high throughput.
Core Concepts
Latest Kaka concepts, step-by-step. First we will see how a message is produced and consumed and the components included in that process.
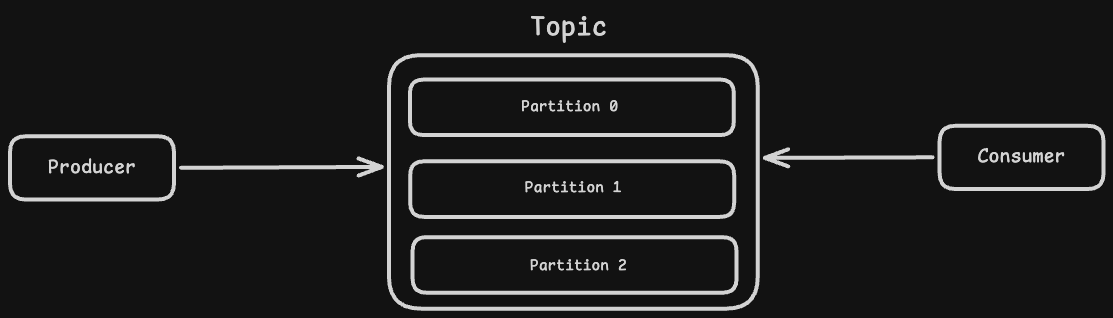
Producer
The producer is the application that is responsible for sending messages to Kaka.
Topic
A topic is a logical category used to organise and store messages. For example, messages related to payment can go to the "payments" topic.
Consumer
The consumer is the application that is responsible for fetching messages from Kafka and processing them.
Partitions
A partition is a subdivision of a topic that allows Kafka to split data for scalability. Each partition stores messages in an ordered sequence, ensuring order within that partition. Partitions enable parallel processing by allowing multiple consumers to read data simultaneously.
Partitions are way more important
Partitions are more important than you think because they provide us with the biggest advantages:
- Parallelism
- Ordering Guarantee
If a topic has three partitions, then three consumers can read from the topic parallelly at a time. This is very important for scalability. When you need to process more data from a parallel topic, you need to create more partitions.
If a message "A" is produced before message "B", then Kaka guarantees that "A" will be consumed before "B". This happens because each partition is an immutable append-only log in which messages are appended in the exact order they are written.
How does Consumer actually get data?
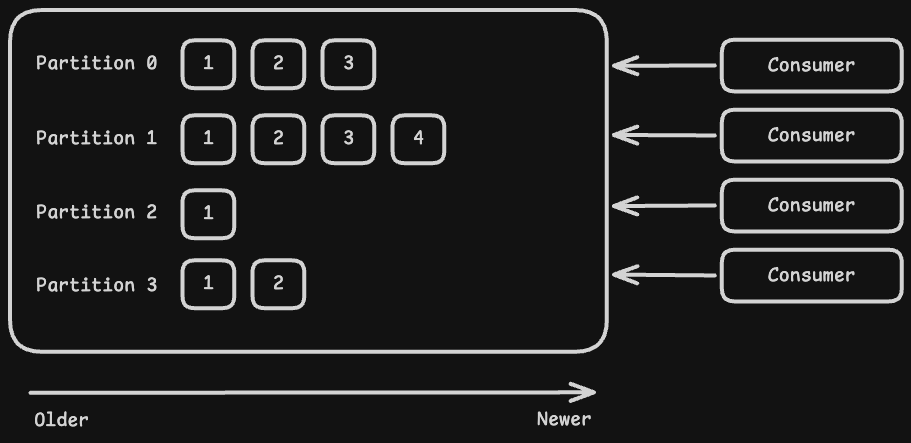
Kafka consumers use a pull-based mechanism to fetch messages. Instead of Kafka saying, "Okay, take this message," to a consumer, the consumer says to Kafka that "we need this message." But the question is how do consumers actually know which message to read? This is where offset comes into play.
In Kafka, an offset is a unique, sequential and immutable integer assigned to each message within a partition. When a consumer starts for the first time, it will start reading from the 0th offset. Once it reads the 0th offset, it can go to the 1st, 2nd, 3rd and so on. Whenever a message is successfully consumed, its offset will be committed by the consumer to Kafka. In case any consumer crashes when a new consumer instance starts, it will use the last committed offset to resume reading from where the previous one left off.
Consumer Group - An important concept
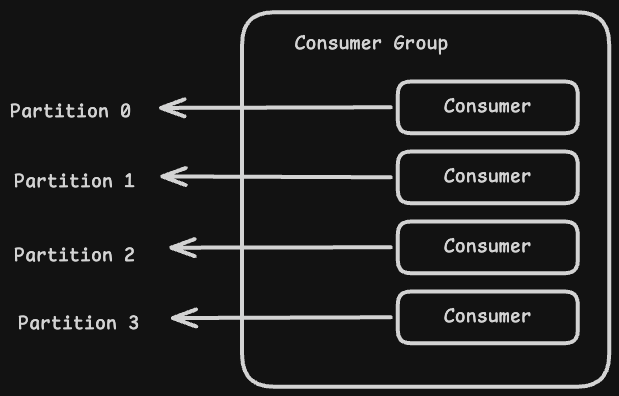
A consumer group is a collection of consumers that work together to consume messages from a topic. Here are a few important points about consumer groups.
- Each partition will be processed by exactly one consumer in the group.
- If there are more consumers than partitions, then some consumers will sit idle.
- If there are fewer consumers than partitions, then some consumers will process multiple partitions.
Consumer groups are used to enable horizontal scalability, high-throughput parallel processing, and fault tolerance.
Kafka Architecture
Broker
A broker is a core server component in Kafka that is responsible for receiving messages from producers, storing them and sending them to consumers. All the magic happens inside this component. It is often referred to as the Kaka server.
Cluster
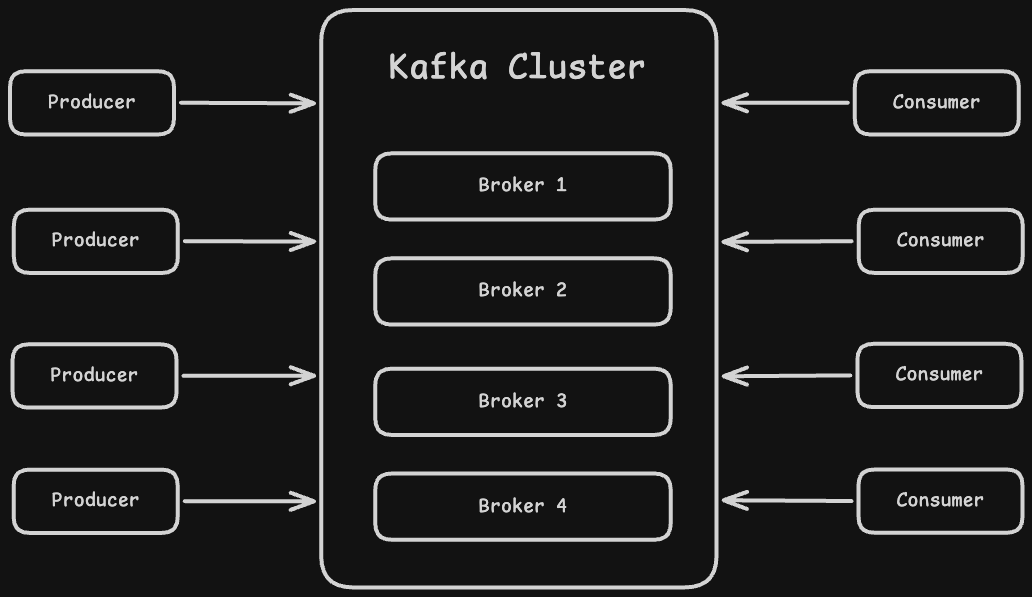
A cluster is a group of multiple brokers working together as a single system. Instead of relying on a single broker, Kafka distributes data across multiple brokers to handle more load and avoid a single point of failure. Each broker in the cluster stores a part of the data and coordinates with others to serve requests. This setup makes Kafka highly scalable and fault-tolerant, meaning even if one broker goes down, the cluster can still continue to operate without data loss.
Zookeeper
Zookeeper is a centralized service used by Kafka to manage and coordinate the cluster. It doesn’t store actual messages, instead it keeps track of metadata about the system.
It is responsible for things like keeping track of brokers, managing which broker is alive or dead, and handling leader election for partitions. Whenever a broker joins or leaves the cluster, Zookeeper is the component that knows about it.
Kafka used Zookeeper because distributed systems need a reliable way to maintain shared state and coordination between multiple nodes. Instead of building this complex logic from scratch, Kafka relied on Zookeeper to handle it.
KRaft
KRaft is Kafka’s new way of managing the cluster without using Zookeeper. Instead of relying on an external system, Kafka now handles its own metadata and coordination internally.
In KRaft mode, a set of brokers form a controller quorum that uses the Raft consensus algorithm to manage cluster state. This includes things like broker registration, topic metadata, and leader election. Everything that Zookeeper used to do is now handled inside Kafka itself.
Data Replication
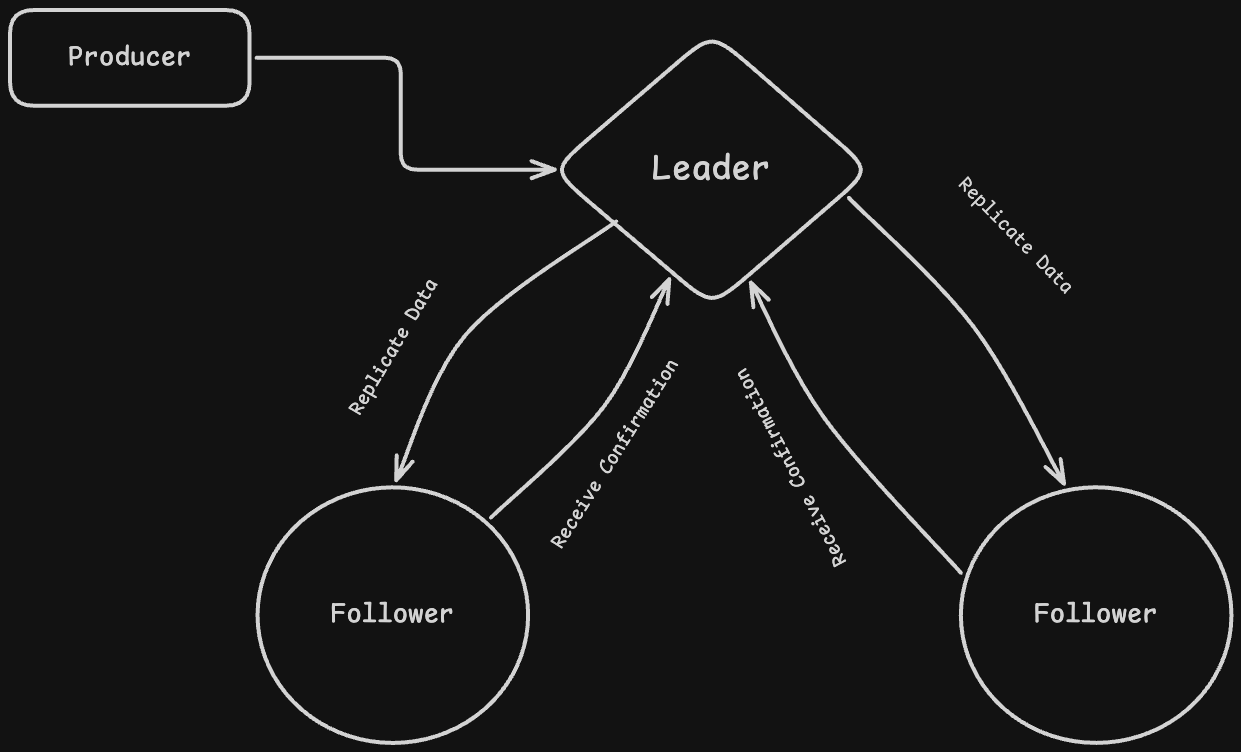
Replication is how Kafka ensures data is not lost. Instead of storing a partition on a single broker, Kafka creates multiple copies of it across different brokers. Each partition has one leader replica and multiple follower replicas. The leader handles all reads and writes, while followers simply copy data from the leader. Whenever a producer sends a message, it goes to the leader first, and then gets replicated to followers. This way, even if one broker goes down, another replica can take over without losing data.
In-Sync Replica
ISR is the set of replicas that are fully caught up with the leader. Not all replicas are always in sync, some might lag behind due to network issues or slow processing. Kafka keeps track of which replicas are “healthy” and up-to-date, and only those are part of the ISR. When a leader fails, Kafka selects a new leader only from the ISR set. This ensures that no data is lost during failover. If a replica is too far behind, it is removed from ISR until it catches up again.
Delivery Guarantees
Kafka provides different levels of delivery guarantees depending on how you configure producers and consumers. This defines how safe your data is vs how fast your system runs.
- At most once - Messages are delivered zero or one time. The consumer reads the message and commits the offset before processing it. If something fails after that, the message is lost.
- At least once - Messages are delivered one or more times. The consumer processes the message first and commits the offset after that. If a failure happens in between, the same message can be processed again.
- Exactly once - Messages are delivered exactly one time with no duplicates and no loss. Kafka achieves this using idempotent producers and transactional APIs.
That's It
So these were the fundamentals that everyone must know. If we go further, we can dive into other concepts such as scaling Kafka, data retention & storage, setting up a Kafka cluster, etc. But in order to keep this post simple and beginner-friendly, we are not going to dive into those.
You May Also Read
- Built a TCP Load Balancer in C to understand how it actually works.
- HTTP Under the Hood: Here's What Actually Happens
- Building a Kafka-style commit log from scratch.
Before You Go
If you made it this far, Thank You.
I usually write about backend engineering, distributed systems, and things I learn while working on real problems. Not theory — mostly practical stuff that I wish someone had explained to me earlier.
I run a free newsletter where I share these kinds of write-ups. No spam. Just occasional backend engineering notes.
